The Meaningfulness of Events via Standardization ( Part 5 )
This is part 5 of the 'Meaningfulness of Events via Standardization' series. In this part, we cover how we can bring the ease of adoption of a standard and remove the burden of adoption in development teams.
Following the establishment of a standardization process incorporating elements such as Documentation, Versioning, Filtering, and Event Envelopes as detailed in the preceding articles, the next step is to implement these standards. This phase poses the greatest challenge, as effective collaboration and communication among software stakeholders play a crucial role in successful adoption.
Governance
Governance in IT has different definitions based on company culture, size, and the value it brings. For this article, Governance is defined as a means to identify the system's complexity, observe system behavior, and simplify the decision-making process.
When dealing with software, Often the source of knowledge is the development team per their detailed vision of implemented business complexity, software communication process, and potential risks behind any change. This is ok on its own but putting this knowledge in a local place being a team and adding some dependencies to people can become an obstacle when speed becomes an important pillar of success.
Software vs People Communication
Back in 2005-2010, Often software was designed using a monolithic approach, where all complexity was localized in a single place. That approach suffered from software complexity, availability, and scaling problems, But there was less network and communication burden being Software or People.
Distributed systems are a solution but in reality, they resolve monolithic suffering points, but adding new problems by distributing software and knowledge into multiple locations and adding a higher level of communication and alignment problems.
EDA is a distributed communication pattern applied at communication boundaries and resolves some distributed system problems by decoupling. But add some level of difficulties over the traditional distributed systems, by reversing the dependency direction. so any degradation will be identified at the subsequence layers behind producer service and not in preceding layers and this makes things harder to be identified.
Decisions
In a competitive business where competitors move by the fastest change rate to approve ideas and bring unique problem-solving ideas into the products, being able to make faster, cleaner, and more accurate decisions about a problem is important.
To this goal relying on data and having enough information become crucial to achieve rapidity and clarity while making decisions. Having detailed data is hard but an approach to deal with when the business needs to move at scale.
Event Cataloging
One of the useful approaches for observing the internal state of a system is cataloging, in the cataloging approach we gather information about the overall system communication like Documentation, Schemes, Versions, and Consumption.
A Catalog must offer a result set to cover the following details
Producers - Who does introduce that change?
Consumers - Who are the interested actors behind that change?
Event Models - What are the event models transiting?
Event Versions - What are the active and outdated event versions?
Service Specifications - What does each producer offer to consumers?
System Communication: How do the systems communicate together
Cloudevents
Cloud events is a new specification for event-driven design approach and helps to put some standards over how the event model must be done. Cloudevents bring the separation of context and data but keep them correlated.
Event definition
The Cloudevents specification describes an event as:
An "event" is a data record expressing an occurrence and its context.
Events are routed from an event producer(the source) to interested event consumers.
The routing can be performed based on information contained in the event, but an event will not identify a specific routing destination.*
Events will contain two types of information: the Event Data representing the Occurrence and Context metadata providing contextual information about the Occurrence.
The takeaways from the above description are :
Events express occurrence and context.
Events are routed so an event transits along many communication hopes before reaching the consumer.
The routing is done based on event information, so the event must provide enough information to simplify routing and event transition.
The Context includes some information about the occurrence, so the context represents even-related information.
Event Transition
As the event-driven architecture is a distributed communication pattern, Event transition is one important point to take into consideration. An event can be transited from any starting point and be consumed in one or more places. The event will be routed along many network or software hops, like a broker, enrichment process or aggregation process.
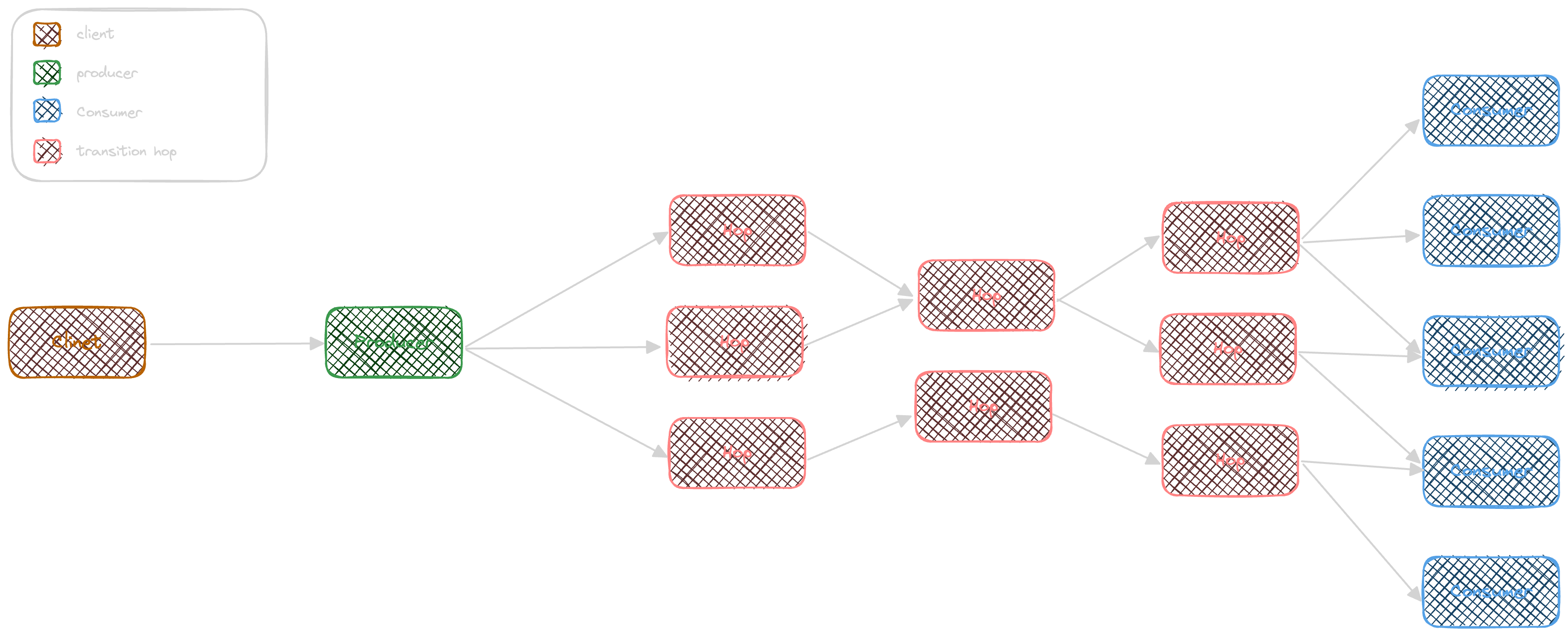
Event Occurrence
An occurrence is a definition of 'What is the change in a process', it is important to well define the occurrence and the principal events in a context but keeping separation between internal state changes and external ones helps to define better and guarantee the distributed communication quality.
Keeping the occurrence internal state helps reduce the distributed communication complexity, by abstracting the internal process from the external process.
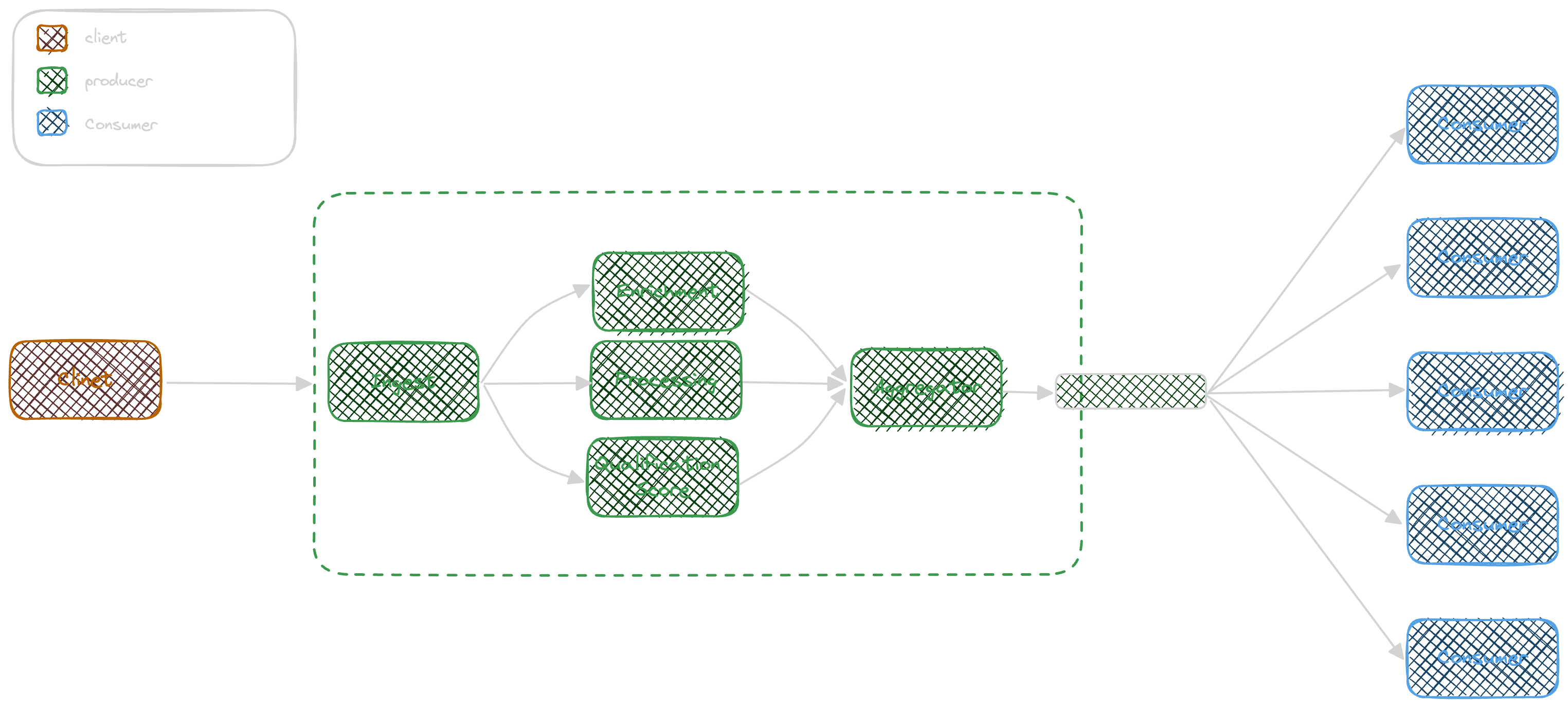
Event Envelope
Looking at a simple envelope, there are two levels of information, a letter inside the envelope, representing the detailed intentional information and some information presented on the envelope like an Identifier, Confidentiality stamp, Sender, and Date.

The internal letter will be interesting when the envelope arrives at its destination and will be in hand. but the external information is useful for tracking, distributing, and routing.
Cloudevents Design Goal
Cloudevents specification represents some standards and principles around the event-driven architecture but the initiative like all other standards is to tackle some real problems.
The goal of the CloudEvents specification is to define the interoperability of event systems that allow services to produce or consume events.
CloudEvents are typically used in a distributed system to allow for services to be loosely coupled during development, deployed independently, and later can be connected to create new applications.
The above is from the cloudevents primer design goal documentation, the primer focuses on the following considerations:
Protocol and Channel agnostic
Extensibility
On top of standards
Channel / Protocol Agnostic
Cloudevents standard relies on the principle of being protocol and channel-agnostic, the specification understands well the presence of different protocols and communication channels in real systems and provides some guidelines to approach them.
The Specification provides guidelines for the following protocols:
AMQP
MQTT
NATS
Websockets
HTTP
Also, The specification represents some guidelines related to channels to address the adoption of a standard on tom of channel presence. Cloudevents introduces the concept of adapters and provides some practices to overcome channels as a mean of event distribution.
Extensibility
Being a specification related to a distributed event-driven architecture, Cloudevents introduces extensions to overcome communication and process problems by using extensions as a standard way of extensibility on top of Cloudevents.
An extension is a set of context-level attributes that help the adoption of standards or practices to tackle an event-driven design problem. extension must follow the primary data types provided by Cloudevents.
Cloudevents supported types are:
Binary: Sequence of Bytes RFC4648.
Integer: Signed 32bit numeric range between -2,147,483,648 to +2,147,483,647 RFC 7159, Section 6
String: Sequence of allowable Unicode characters
Boolean: True or False
Timestamp: RFC 3339.
URI: Absolute URI RFC 3986 Section 4.3.
URI-Reference: Relative URI RFC 3986 Section 4.1.
Cloudevents available extensions are:
Distributed Tracing: The extension goes on top of Open Tracing standard.
Expirytime: solves the event validity problem
Sequence: solves the event ordering problem
Partitioning: Solves the scaling problem by adding the related partition key to events to help brokers and consumers better identify events.
Dataref: Solves the problem of large event payload by producing the payload file/storage location as part of a smaller event.
Authcontext: solves the problem of identifying the principal or actor initiating the occurrence.
Putting Cloudevents on AWS
AWS provides a wide range of infrastructure including communication channels that help to distribute the events between different software such as Event Bridge, SQS, SNS, and kinesis. choosing the right service per requirement is an important part of design.
Implementing examples
The provided example represents a distributed event-driven approach for an e-commerce software system.

The example source can be found in the following GitHub repository, Follow the Readme instructions to deploy and test the provided examples
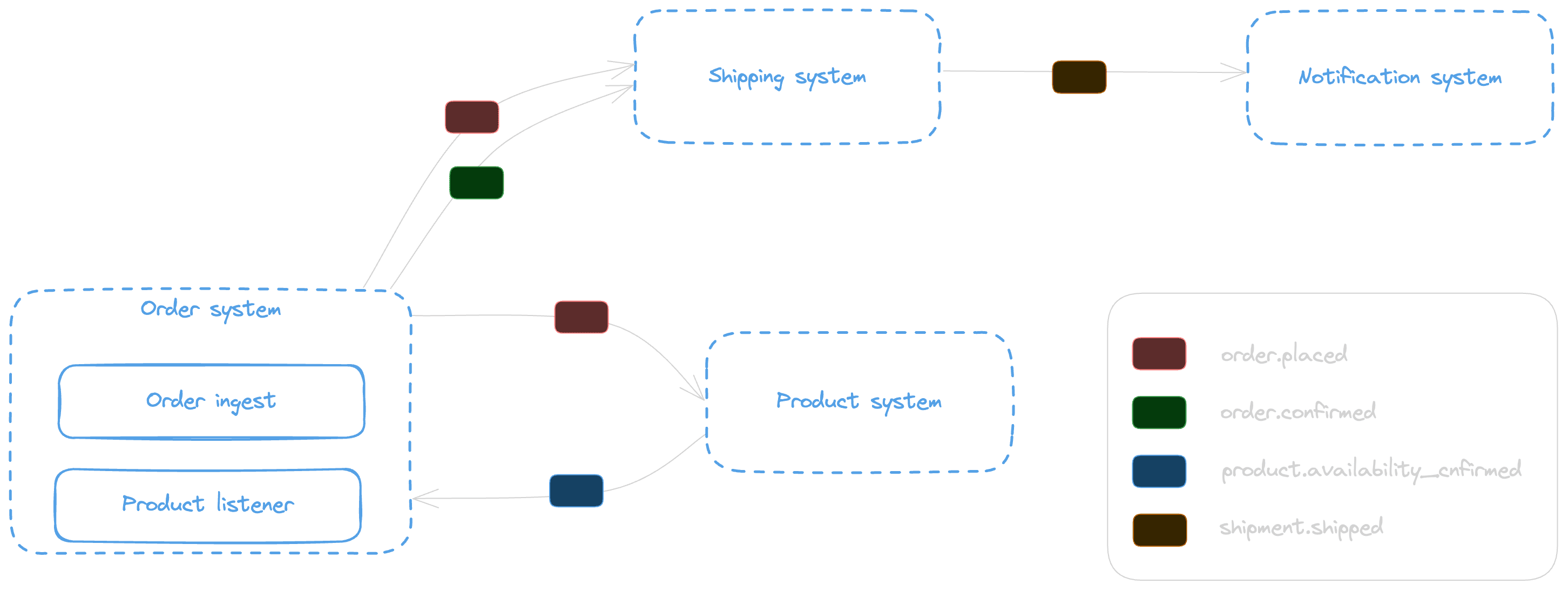
The above design follows a simple basket item approval leading to an order validation and delivery process.
The basket item approval command reaches the order system.
The ordering system distributes an event of type order.placed
The Shipment system starts preparing the packaging
The product system validates the availability of the product
The order system listens to product availability
If the product is available, distribute an order.confirmed event
If the product is not available distribute an order.cancelled event
The Shipment system sends order.shipped event if received an order.confirmed event
The Notification system listens to order.shipped events
Order system
The Order System has two modules, The ingestion is responsible for receiving the orders and the product listener is responsible for acting behind any product state change.
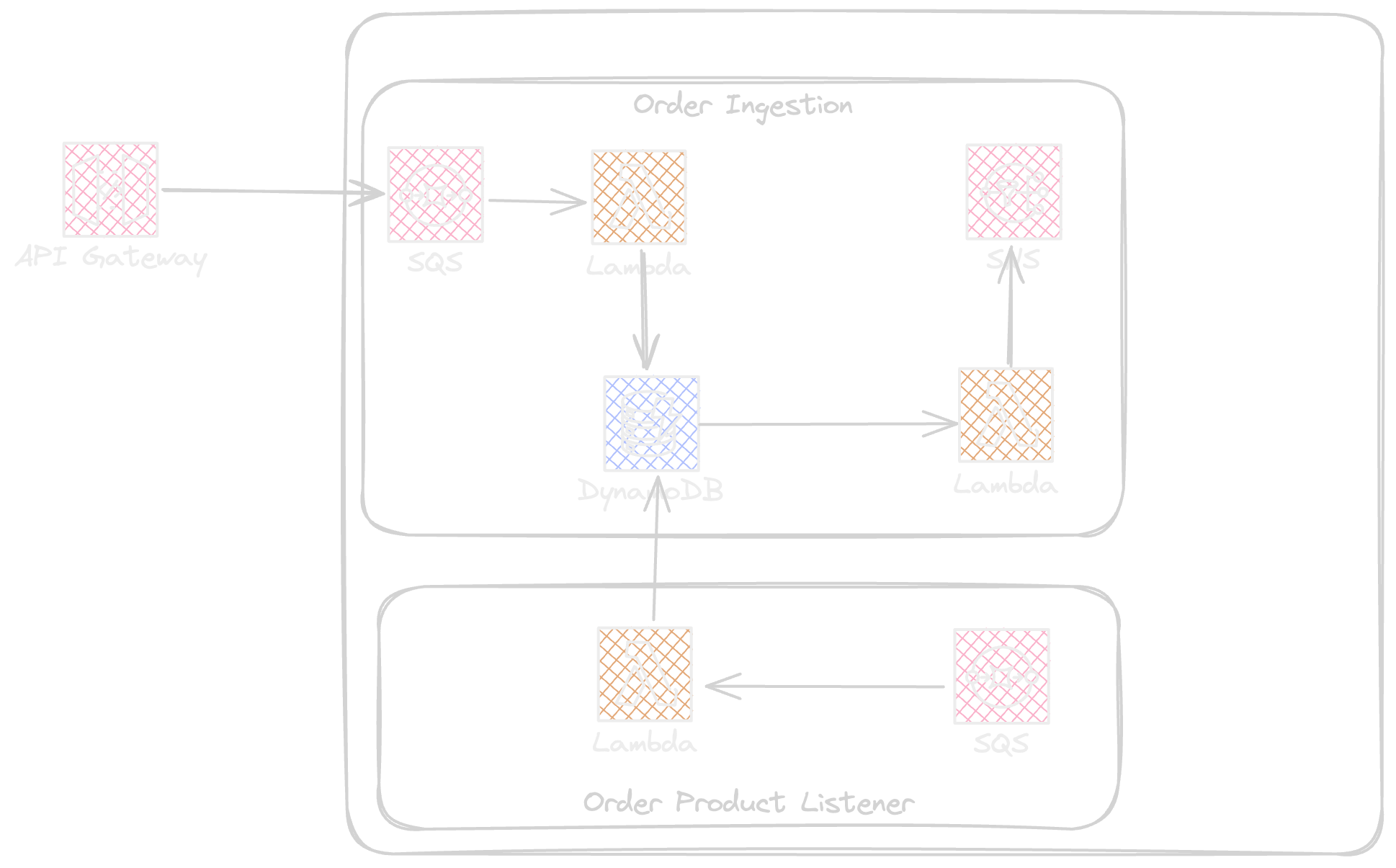
The ingestion receives the basket.item-approved event that is an event respecting cloudevent standard envelope, coming over HTTP protocol using ApiGateway.
The integration of ApiGateway and SQS using AWS CDK takes care of considering headers and body and adapting them as a standard event payload. The approach is what cloudevents adapter specification represents.
private static readonly sqsRequestTemplate = `Action=SendMessage&MessageBody={
"data" : $util.urlEncode($input.body),
#foreach($param in $input.params().header.keySet())
"$param": "$util.escapeJavaScript($input.params().header.get($param))" #if($foreach.hasNext),#end
#end
}`
The order DDB stream lambda sends multiple versions of order.placed to an SNS topic.
Product System
The product system is a subscriber of the order system, listening to order.placed events using a SQS queue. the SQS is configured with RawMessageDelivery at SNS subscription level. this helps to avoid the message being wrapped in an SNS envelope. ( AWS RawMessageDelivery Documentation )
The SNS/SQS subscription adaptation must be done in two steps IAC adapter using RawMessageDelivery and Software adapters to fetch the event out of wrapped event in SQS event model.
ordersTopic.addSubscription(new SqsSubscription(productsQueue, {
rawMessageDelivery: true,
filterPolicyWithMessageBody: {
source: FilterOrPolicy.filter(SubscriptionFilter.stringFilter({
allowlist: [
'ecommerce.orders.service'
],
})),
type: FilterOrPolicy.filter(SubscriptionFilter.stringFilter({
allowlist: [
'order.placed'
],
})),
dataversion: FilterOrPolicy.filter(SubscriptionFilter.stringFilter({
allowlist: [
'v1.0'
],
})),
}
}))
The product system listens to v1.0 of order.placed event, so if any new version of order.placed will be introduced, this will not impact or introduce duplicated reception in product system.
The snippet shows the code adapter to retrieve the envelope from SQS event model.
import { EventBridgeEvent, SNSEvent, SQSEvent } from "aws-lambda";
import { EventModel } from "../models/cloud-event";
type EventType = SQSEvent | SNSEvent | EventBridgeEvent<string, any> | EventModel<any, any> | any;
const getEvent = <T,U>(
event: EventType
): EventModel<T,U> | Record<string, any> | null => {
...
if( event.Records[0].eventSource == "aws:sqs" )
return JSON.parse(event.Records[0].body);
...
return null;
}
export const DeSerialize = <T,U>(
event: EventType
):EventModel<T,U> | Record<string, any> | null => {
const evt = getEvent<T,U>(event);
console.log({
...evt,
recipient: process.env.SOURCE,
});
return evt;
}
Shipment System
The shipment system listens to all order.placed, confirmed, and cancelled events, and listens to v2.0 of events.
ordersTopic.addSubscription(new SqsSubscription(productsQueue, {
rawMessageDelivery: true,
filterPolicyWithMessageBody: {
source: FilterOrPolicy.filter(SubscriptionFilter.stringFilter({
allowlist: [
'ecommerce.orders.service'
],
})),
type: FilterOrPolicy.filter(SubscriptionFilter.stringFilter({
allowlist: [
'order.placed',
'order.cancelled',
'order.confirmed'
],
})),
dataversion: FilterOrPolicy.filter(SubscriptionFilter.stringFilter({
allowlist: [
'v2.0'
],
})),
}
}))
Notification System
The shipment service sends the events to an event bridge bus, and the Notification system listens to the shipment service using an event bridge rule.
The rule removes extracts $.details representing the Cloudevent respected event from the EventBridge wrapped event payload.
new Rule(this, 'rule', {
eventBus: shipmentEventBus,
eventPattern: {
detail: {
type: ['order.shipped'],
source: ['ecommerce.shipment.service'],
dataversion: ['v1.0']
}
},
targets: [
new targets.SqsQueue(notificationQueue, {
deadLetterQueue: dlq,
message: RuleTargetInput.fromEventPath('$.detail'),
}),
]
});
Producing Events
The producers of events use a helper method to generate the events, the method will generate an Event Id, Idempotency key , correlation Id, sequence id, and accepts the event type , event payload, version, and causation id as parameters.
export const InitEvent = <TData, TEventType>(
source: string,
eventType: TEventType,
eventData: TData,
dataVersion: string,
dataSchema?: string,
causationId?: string,
correlationid?: string
): EventModel<TData, TEventType> => {
return {
idempotencykey: uuidV5(JSON.stringify(eventData), "40781d63-9741-40a6-aa25-c5a35d47abd6"),
id: nanoid(),
time: new Date().toISOString(),
data: eventData,
type: eventType,
source,
dataversion: dataVersion,
dataschema: dataSchema,
causationid: causationId,
correlationid: correlationid ?? nanoid(),
specversion: "1.0.2",
sequence: ulid(),
}
}
The Idempotency key helps to avoid unintended behavior on the consumer side in case of event duplication.
The Sequence helps to keep track of the ordering of events on the consumer side.
Observing Events
To observe the event production and consumption for simplicity we use cloudwatch service, the goal is to discover how the cloudevent context info is important to be observed.
As the events can reach the lambda service from different services using the adapter concept to extract the event payload is the proposed approach by cloudevents. All lambda handlers in this example use a custom Deserialize helper to extract the Cloudevent model from the infrastructure event.
export const DeSerialize = <T,U>(
event: EventType
):EventModel<T,U> | Record<string, any> | null => {
const evt = getEvent<T,U>(event);
console.log({
...evt,
recipient: process.env.SOURCE,
});
return evt;
}
The helper function logs the cloudevent event payload to simplify the observability and data extraction.
Running the example
The source code provides a Postman collection in 'assets' folder under Cloudevents.postman_collection.json name, to run it simply import the collection in postman and change the request URL by the ApiGateway url returned at the end of orders system deployment. or use the following curl command to send an event.
curl --location 'https://xxxxxxxx.execute-api.eu-west-1.amazonaws.com/live/sqs' \
--header 'x-api-key: ec1a9e8f-b8fc-4a6d-9069-108775d67af8' \
--header 'causationid: 6e67e1a4-e323-492e-a7ff-a489a54ba63d' \
--header 'source: ecommerce.baskets.service' \
--header 'type: basket.item-approved' \
--header 'id: 872fab6b-4f22-4951-874d-021d68d39154' \
--header 'specversion: 1.0.2' \
--header 'time: 2024-04-06T22:40:33.413Z' \
--header 'dataversion: v1.0' \
--header 'correlationid: 3a02915a-ba3e-4e58-b7c3-642efaa31a1a' \
--header 'Content-Type: application/json' \
--data '{
"orderDate": "2024-01-01T12:55:00.990Z",
"price": 1000,
"quantity": 2,
"productId": "PRD_12345643",
"userId": "a5449147-ab45-4bec-a0be-f00daf5f2871"
}'
The process behind this request will place an order but the order will be canceled later because the product availability will not be confirmed by the lack of product in the product system DynamoDB table.

As represented we can observe the event type and version consumption. and see the event transition process. To simulate the process for an available product we can add the following product in the table.
{
"productId": "PRD_12345643",
"price": 500,
"stock": 1,
"status": "IN_STOCK"
}
Sending a new request will result a full order process, including confirmation and shipment approval.

Also extracting some statistics helps to see the active consumption and for example find outdated event versions and active ones.
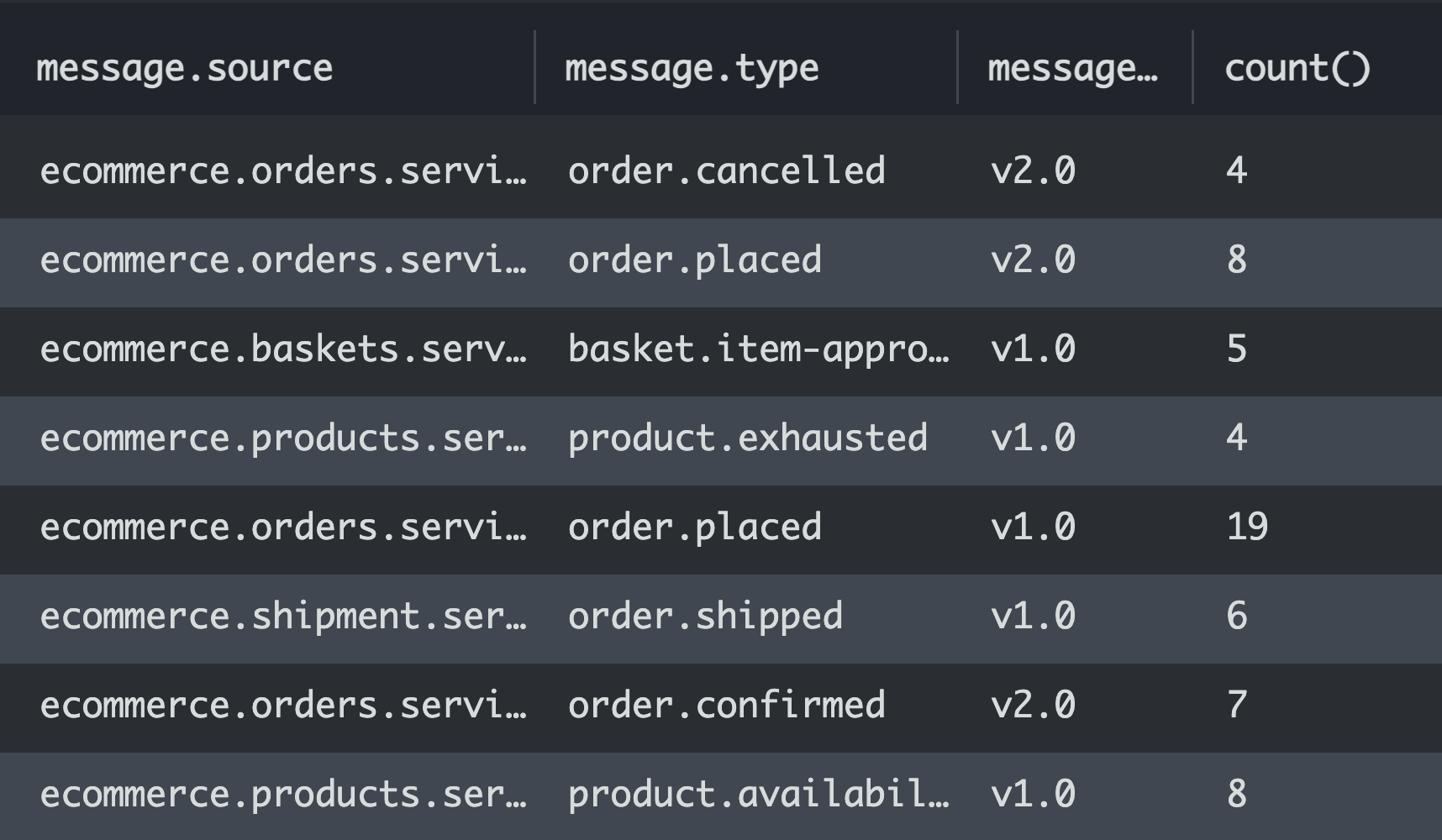
Event Discovery
As the example already uses the cloudwatch, to prepare a catalog of events use of lambda extensions can be a solution to achieve event discovery and schema extraction and documentation.
The following design demonstrates how lambda extensions can be used as a sidecar to feed the event discover process.
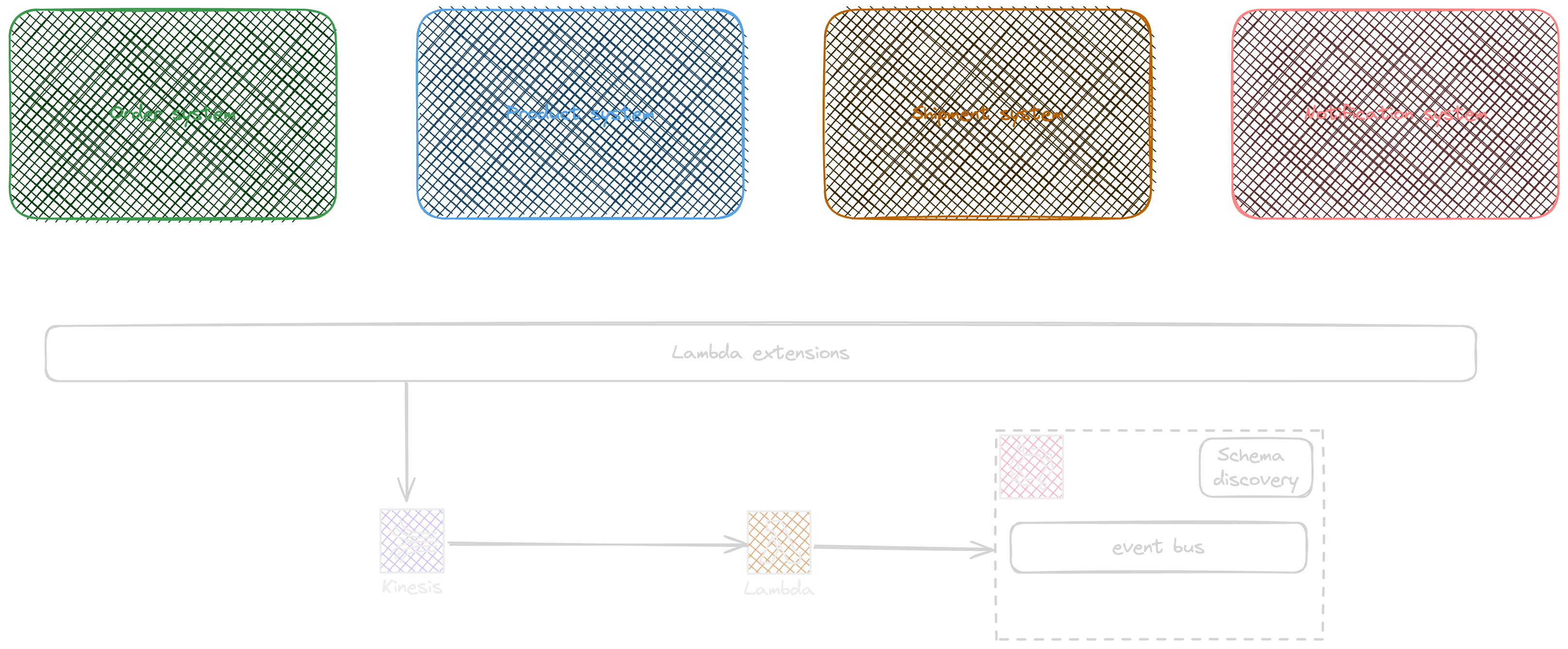
The extension receives the logs and moves them to a kinesis data stream that results in triggering a lambda function that puts events into an EventBridge custom bus with an enabled discovery option.
The extension subscribes to the lambda telemetry api by registering to the extension api to receive the Invoke and shutdown invocations.
const RUNTIME_EXTENSION_URL = `http://${process.env.AWS_LAMBDA_RUNTIME_API}/2020-01-01/extension`;
await fetch(`${RUNTIME_EXTENSION_URL}/register`, {
method: 'post',
body: JSON.stringify({
'events': [
'INVOKE',
'SHUTDOWN'
],
}),
headers: {
'Content-Type': 'application/json',
'Lambda-Extension-Name': basename(__dirname),
}
});
Also, the extension needs to subscribe to the telemetry api and provide a HTTP listener to allow the telemetry api send the logs to the extension.
Adding the extension to the lambda can be done as shown in the following CDK code.
const orderPlacedFunction = new NodejsFunction(this, 'OrderPlacedFunction', {
entry: resolve(join(__dirname, '../../src/service/ingestion/order-receiver/index.ts')),
handler: 'handler',
...LambdaConfiguration,
role: orderPlacedFunctionRole,
layers: [
telemetryExtensionLayerVersion
],
environment: {
SOURCE: 'ecommerce.orders.service',
TABLE_NAME: this.OrdersTable.tableName,
}
});
The example has the extension attached to all lambda functions, this will send all logs to the kinesis data stream for all functions and let the schema-registerer send those logged events to the custom event bus.
The schema-registerer function has a simple logic as below
await Promise.all(event.Records.map(async (record) => {
const eventData = JSON.parse(Buffer.from(record.kinesis.data, 'base64').toString('ascii'));
await client.send(
new PutEventsCommand({
Entries: [
{
EventBusName: process.env.EVENT_BUS_ARN!,
Detail: JSON.stringify(event),
Source: event.source,
DetailType: `${event.type}.${event.dataversion}`
},
],
}),
);
}
In the above example, the DetailType in PutEvents call is a concatenation of type and version
After sending a request the event schemas will be available in the schema section of the EventBridge.
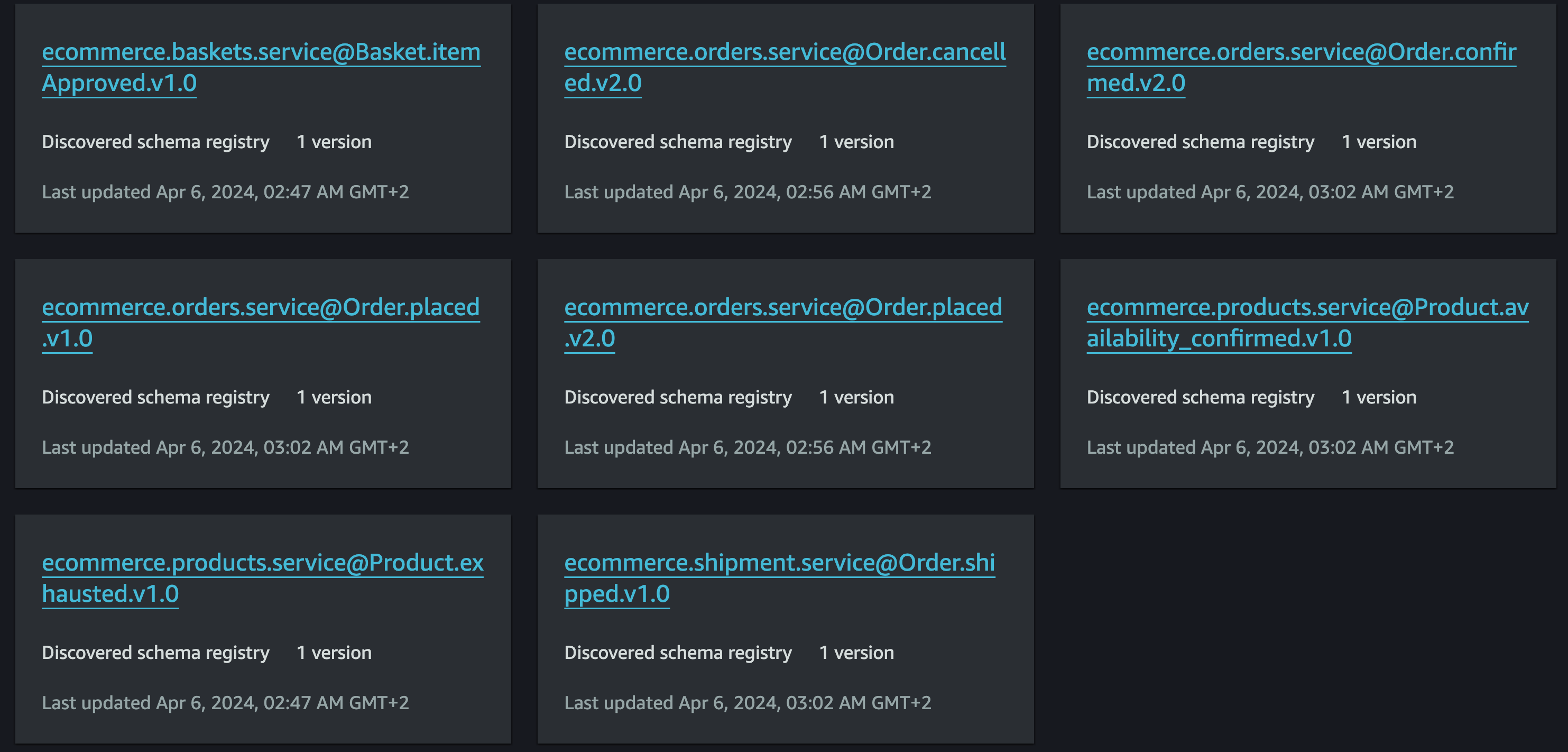
Cataloging
Automation and documentation are two principal points in governance where we capture how the system behaves, and completing everything in an automated manner will be one important part of that journey.
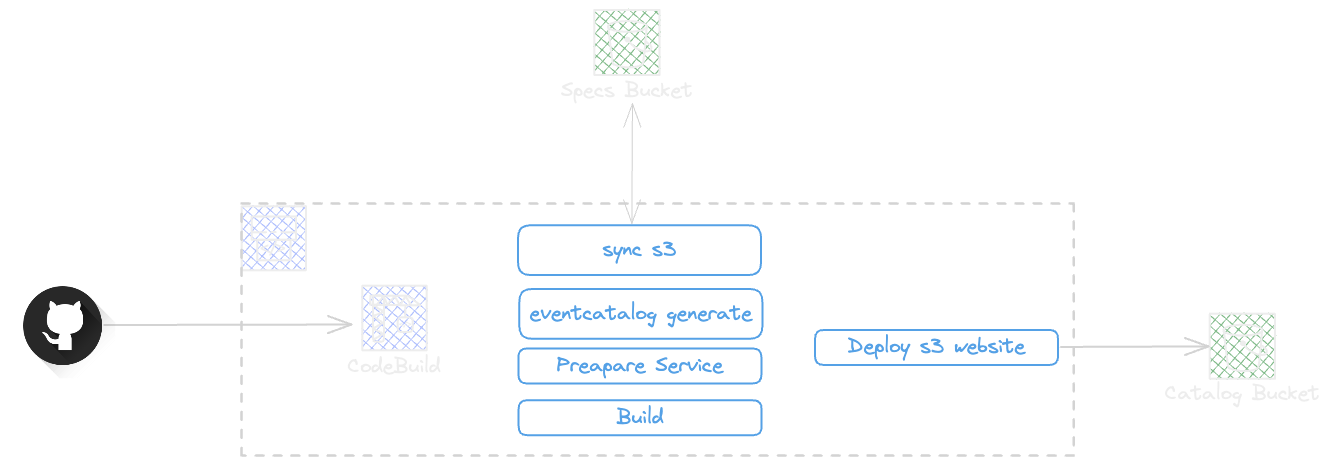
In the above solution, The catalog will be generated using GitHub trigger and aws Code Pipeline, The pipeline will generate, build, and deploy the EventCatalog as a static website.
The source of AsyncApi specs will be a s3 bucket with a domain-based scaffolding as below.
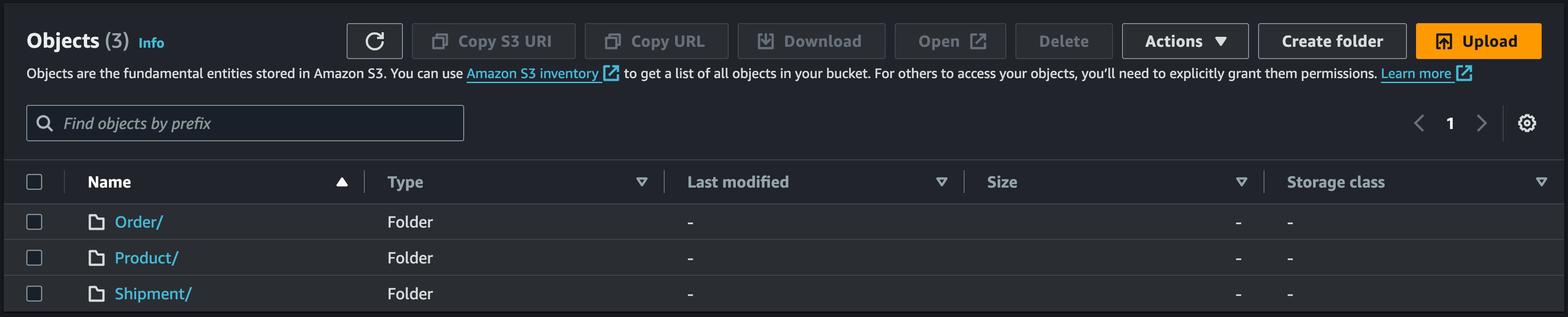
The pipeline build process will Synchronize the s3 bucket to the local folder and generate the Domain, service, and events followed by building the eventcatalog bundle.
version: 0.2
env:
parameter-store:
SPEC_BUCKET_NAME: /catalog/bucket/specs/name
phases:
install:
commands:
- echo Installing dependencies...
- npm cache clean --force
- cd catalog && npm install --froce && cd ..
pre_build:
commands:
- echo "Pre build command"
- mkdir specs
- aws s3 sync s3://$SPEC_BUCKET_NAME/ specs
build:
commands:
- cd catalog
- npm run generate
- npm run build
artifacts:
files:
- '**/*'
base-directory: catalog/out
The catalog project has two stacks, the pipeline stack and the catalog stack, the catalog stack represents the following diagram.
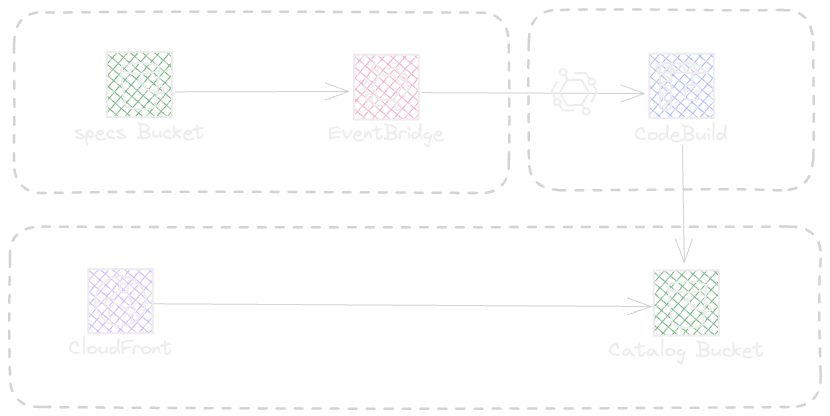
The Catalog and Pipeline stacks can be found as part of the source code in './src/platform/cdk'
AsyncApi Spec will be uploaded in Specs Bucket
The Event bridge will trigger the code pipeline
The Pipeline will Sync all Specs in s3 and regenerate the EventCatalog
The Static S3 WebSite will get updated by new bundle
Catalog of Thousands of Services
The above cataloging section focused on a simplified way of automating the Catalog generation but there is a last question to answer, How we manage thousands of Specs under ownership of hundreds of teams?
The answer is, a service owns the software and all corresponding documentation being OpenApi, AsyncApi, Readme, etc., By defining the spec under ownership of a team and as part of service source code, we need a way to simplify the cataloging in a central and automated way by relying on each service spec in each service repository.
Github actions are a good candidate to replicate the AsyncApi spec and make a copy in specs bucket. The original workflow will be a bit verbose as below
Github offers reusable workflows that can simplify the process of adoption in service teams, for this article simplicity a simple workflow action is the choice
name: AsyncApi Spec Sync
on:
push:
branches: [ main ]
env:
AWS_REGION: eu-west-1
jobs:
sync_spec:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@master
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ env.AWS_REGION }}
- name: Sync spec to S3
run: |
aws s3 sync ./spec s3://$(aws ssm get-parameter --name "/catalog/bucket/specs/name" | jq -r '.Parameter.Value')/
The sync will trigger the regeneration process and update the website.
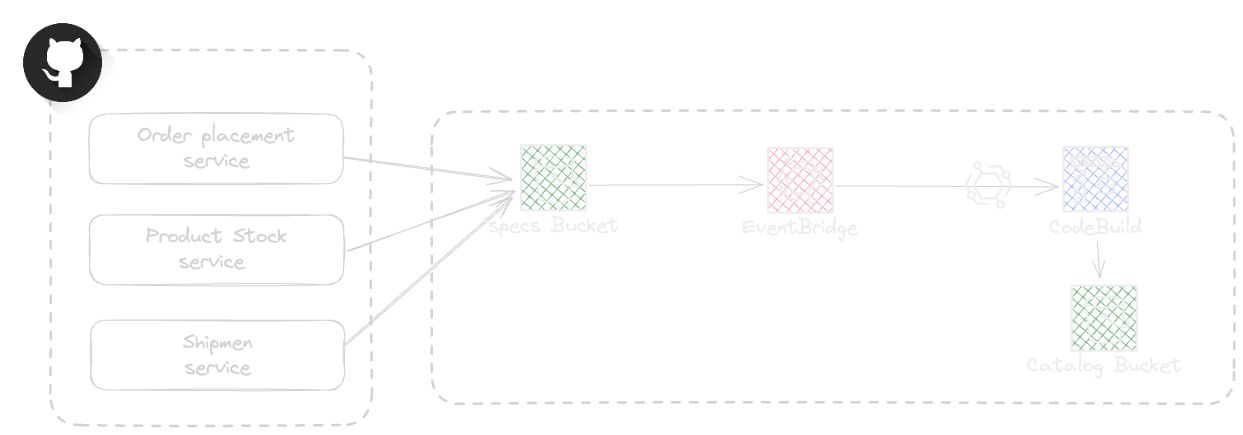
The EventBridge rule listens to default event bus and trigger the Catalog CodePipeline when event changes are pushed to the bus. The EB rule using AWS CDK will be as below.
new Rule(this, 'rule', {
eventPattern: {
source: ['aws.s3'],
detailType: [
'Object Created',
'Object Deleted'
],
resources: [ props.specsBucket.bucketArn ]
},
targets: [ new CodePipeline(pipeline) ]
});
To receive the S3 event notifications to the EventBridge default bus the parameter must be enabled on S3 bucket.
this.specsBucket = new Bucket(this, 'CatalogSpecsBucket', {
objectOwnership: ObjectOwnership.BUCKET_OWNER_ENFORCED,
removalPolicy: RemovalPolicy.DESTROY,
autoDeleteObjects: true,
eventBridgeEnabled: true
});
Event Catalog Config
The event catalog use a generators section as part of the config file to execute AsynAPI plugin. the config looks like the following snippet.
const path = require('path');
module.exports = {
... ,
generators: [
[
'@eventcatalog/plugin-doc-generator-asyncapi',
{
pathToSpec: [
path.join(__dirname, '../specs/Order/1.0.0', 'asyncapi.yaml')
],
versionEvents: false,
renderNodeGraph: true,
renderMermaidDiagram: true,
domainName: 'Orders System'
},
],
[
'@eventcatalog/plugin-doc-generator-asyncapi',
{
pathToSpec: [
path.join(__dirname, '../specs/Product/1.0.0', 'asyncapi.yaml')
],
versionEvents: false,
renderNodeGraph: true,
renderMermaidDiagram: true,
domainName: 'Product System'
},
],
[
'@eventcatalog/plugin-doc-generator-asyncapi',
{
pathToSpec: [
path.join(__dirname, '../specs/Shipment/1.0.0', 'asyncapi.yaml')
],
versionEvents: false,
renderNodeGraph: true,
renderMermaidDiagram: true,
domainName: 'Shipment System'
},
],
]
}
For the moment, the article has no solution to sync the config generators section in an automated way, so here for any new service there is a bit of effort adding the service.
Run the solution
The only required step to trigger the catalog generation process is to push a change to the main branche. this will trigger the s3 sync from local folder.
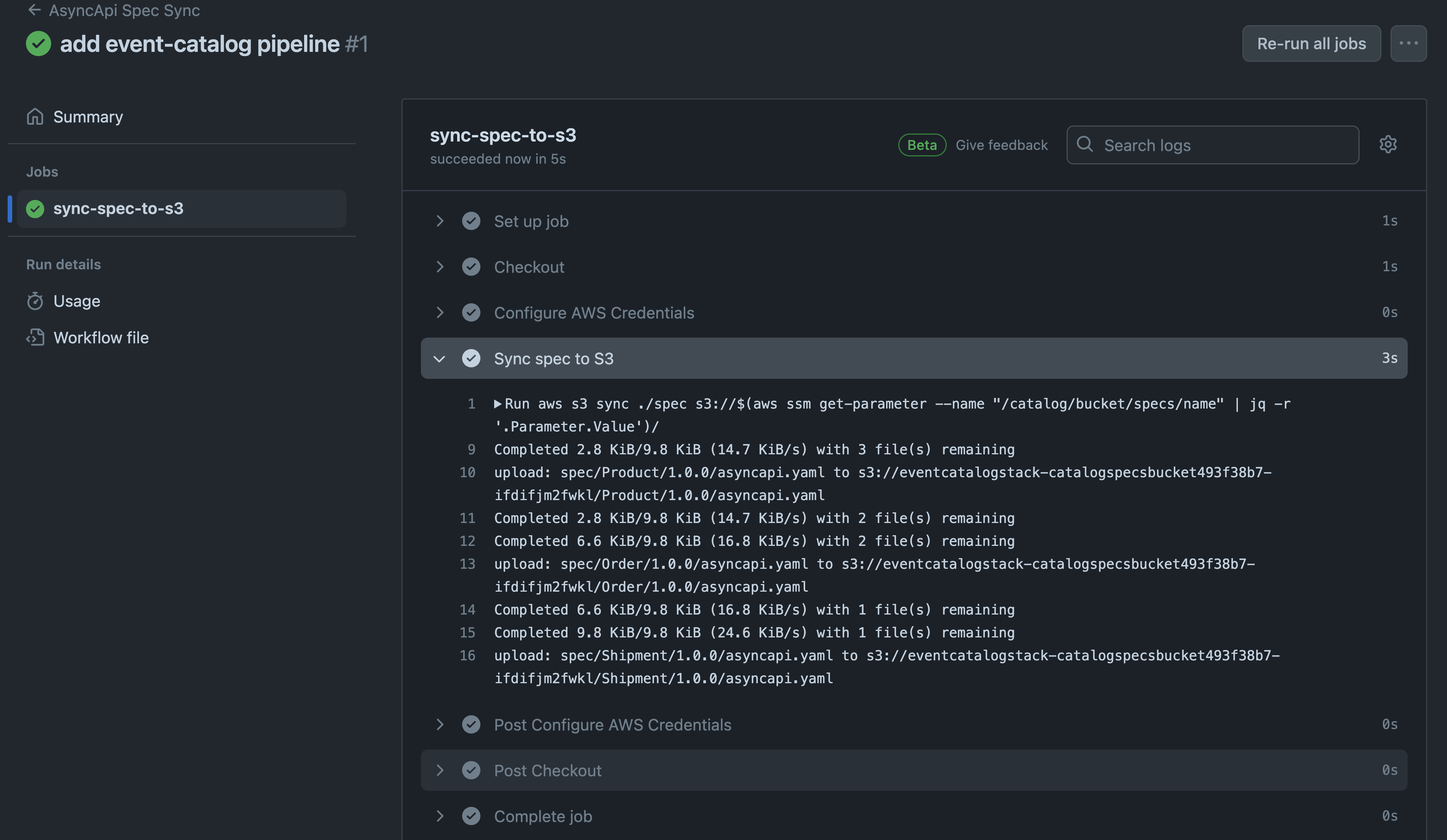
The S3 sync action will lead to the event bridge rule event match and trigger the catalog pipeline

Using the CloudFront distribution url the event catalog will be online and available

Conclusion
The distributed systems are really hard and when it comes to EDA in some mesures the pain-points of distributed system stays with an additional level of complexity that will not be visible in the start of EDA adoption journey, but becomes a real obstacle when system evolves and lots of services communicate using events.
The EDA being a great candidate for agility can become a break of agility without having a minimum of standards. in this article we had a look at a simplified journey of putting standards , operating and observing them. for sure there are the missions parts that can varie per company size , culture and existing tools but the idea stays the same.
Enjoy reading